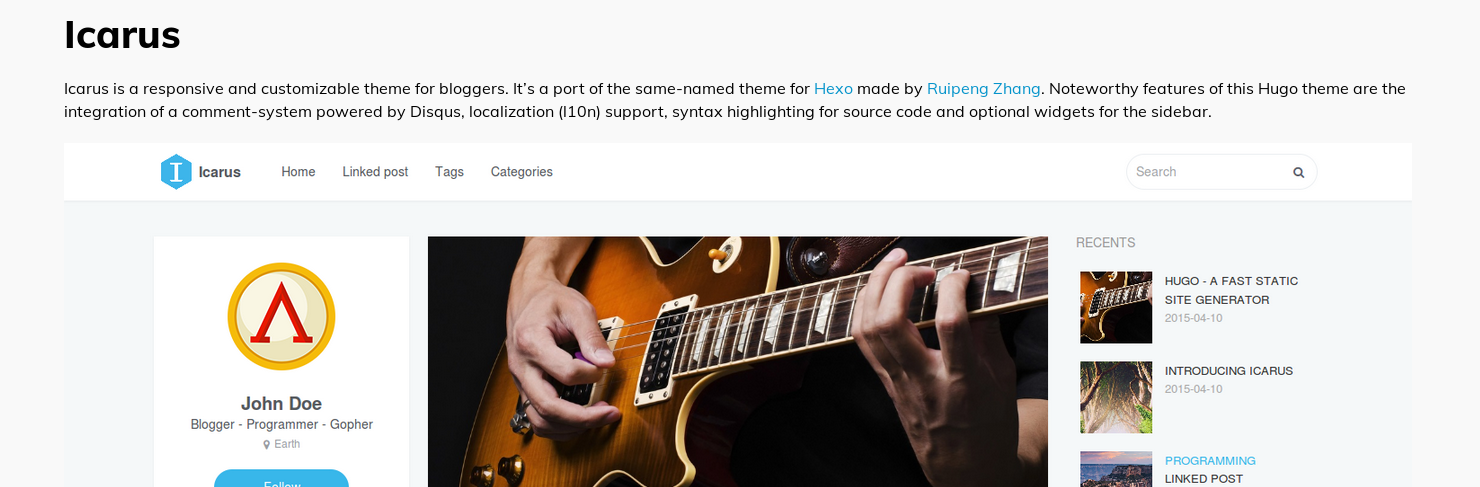
In my post from last week about migrating from Googles Blogger to Hugo I mentioned that the hugo-minimalist-theme has been configured. This is not the case anymore, The site currently uses the Icarus theme, It has been modified a little to redirect site-wide searches to DuckDuckGo instead of Google. At one point I might figure out how to do that nicely and can send the change to the author of the theme.
| Home | Tags |